Leveling up our core speech recognition systems at Speak
June 10, 2024
Authors: Jose Picado, Lakshmi Krishnan, Tobi Szuts, Sean Kim, Tyler Elko, Tuyet Cam
At Speak, our mission is to reinvent the way people learn, starting with language. Our app is an AI language tutoring product that uses streaming automatic speech recognition (ASR) to understand and provide feedback to our English learning users. Our entire core experience is optimized to allow our learners to speak out loud, a lot.
Fast modern streaming ASR systems today are far, far better than 7 years ago when we started Speak, but still fail for our use-case. These systems use machine learning models that have been trained with many tens of thousands of hours of speech audio data, typically largely from native speakers. However, they often struggle to accurately transcribe heavily-accented speech from beginner non-native speakers.
Our app provides immersive lessons that contain a variety of speaking exercises where learners receive immediate feedback on their communication. Therefore, it’s critical for us to have a scalable, low latency speech recognition service that’s both very fast and highly accurate at recognizing heavily-accented English speech from our beginner learners.
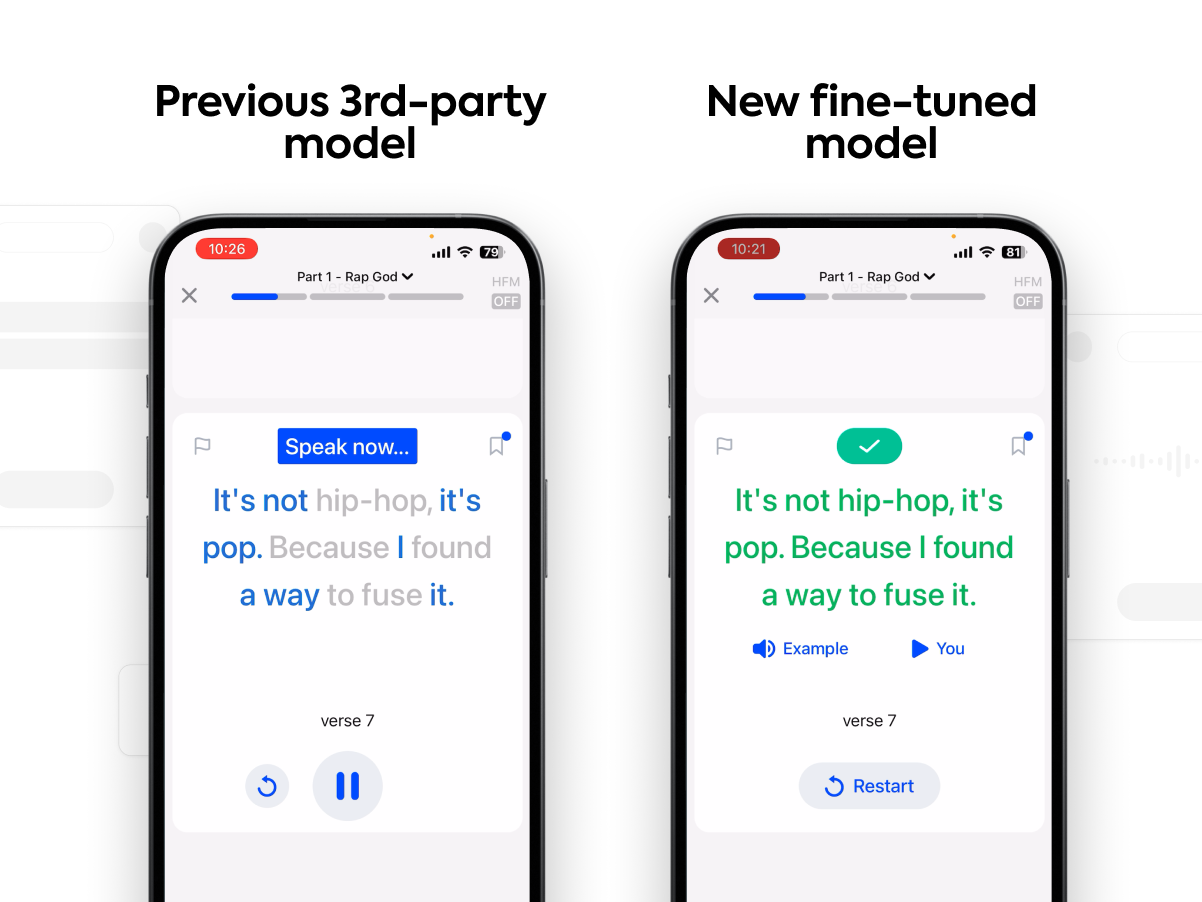
We’ve recently shipped a major upgrade to our core speech recognition systems and infrastructure at Speak. In this post, we'll dive into the technical details of how we did it and some of the real-world technical challenges we had to overcome.
Speech systems fragmented across platforms
The Speak app is available on both iOS and Android. In the past, we operated distinct ASR systems for each platform, using both custom on-device models trained with our own data and 3rd-party speech recognition services. This setup created challenges and technical debt over time:
- On-device models were challenging to handle. The need to support a very long tail of older devices forced us to use smaller and less powerful model families.
- 3rd-party speech recognition services often fail to handle our learners’ very accented speech effectively—a significant issue given our diverse user base that led to a subpar experience for many users.
- We had to maintain two entirely separate speech systems for iOS and Android. This doubled the amount of effort required to update, support, and upkeep our ASR system. We apply a significant amount of application & business logic to how we process raw speech recognition results and provide effective feedback to users. This logic was duplicated and fragmented across clients.
Leveling up our speech systems
To solve this, we decided to improve our core speech recognition systems in two main ways:
- Train a better streaming speech recognition model on our own internal dataset, composed of thousands of hours of heavily-accented English speech audio from Speak learners. This fine-tuned model dramatically outperforms the pretrained model with a >60% reduction in word error rate for our learners and task type.
- Rearchitect our core speech infrastructure into a single unified backend system, encompassing both ASR model inference and post-processing logic. This shift to full backend processing let us employ larger, more accurate speech models as well as unify all business logic in one place, simplifying maintenance and ensuring uniform performance across all users and devices.
Fine-tuning a new speech model
We trained the Conformer family of speech recognition models, which merge self-attention and convolution modules; the self-attention layers learn global dependencies while the convolution layers learn local dependencies of the audio sequences.
Specifically, we selected the Conformer-CTC variant, which uses both CTC loss and decoder—a better fit for fast streaming inference with time alignment between the input and output sequence. We fine-tuned Conformer-CTC with a proprietary dataset composed of many thousands of hours of heavily-accented English speech across many native languages from our learners around the globe.
Using Nvidia’s NeMo framework, a robust open-source toolkit for research and development of speech and large language models, we were able to handle this large dataset effectively and accelerate distributed training and model development.
Evaluating model performance
For model evaluation, we built a custom test set composed of several hours of human-labeled speech from internal Speak data. Our main evaluation metric is word error rate (WER), a standard recognition accuracy metric that compares the number of incorrectly transcribed words against the total number of words spoken.
Our fine-tuned model improved WER for our users by over 60% from the pre-trained model, a significant advance because our dataset is exactly in-domain and encompasses a broad range of heavy accents that off-the-shelf models still struggle with.
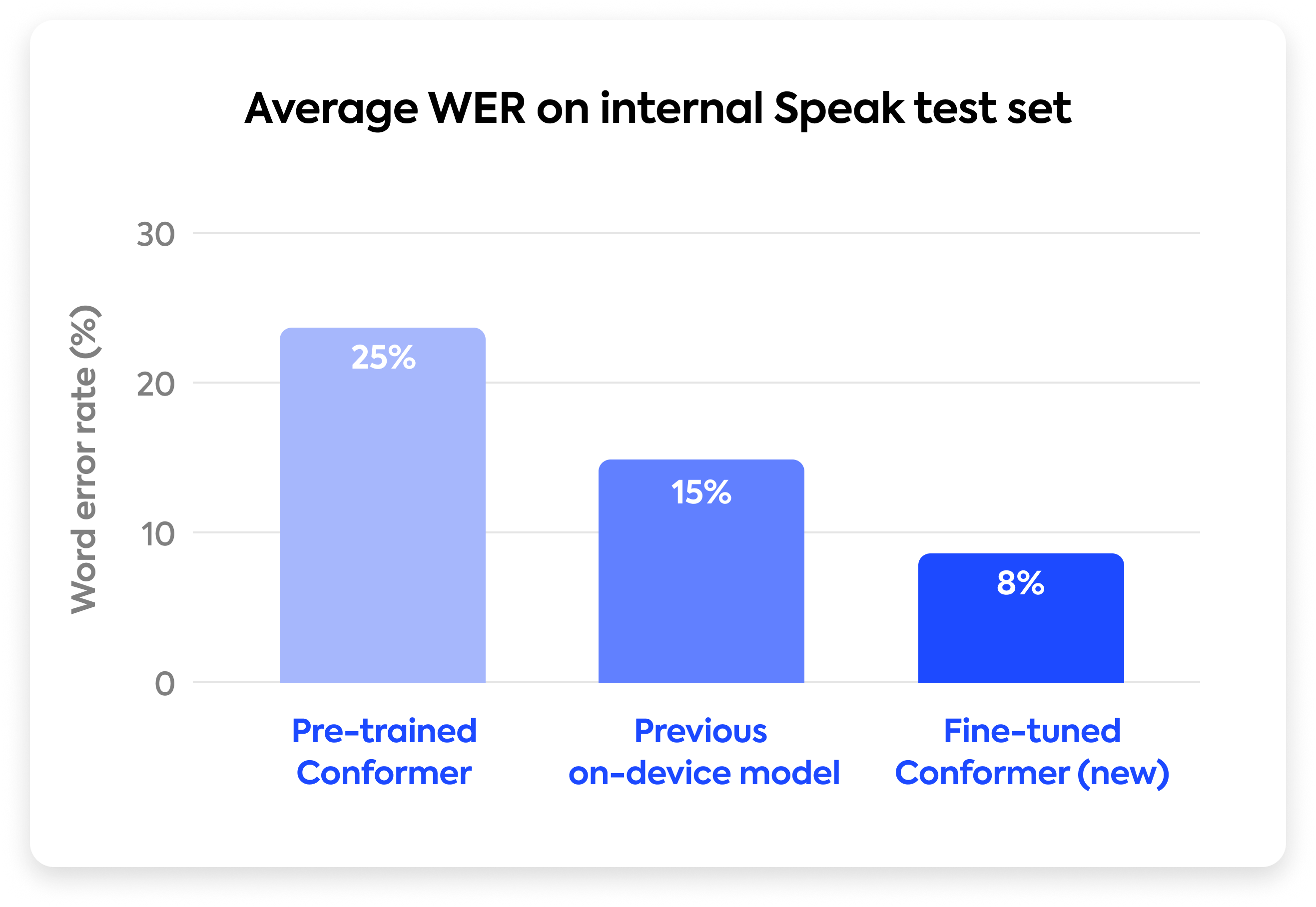
Additionally, we benchmarked our new model against an earlier fine-tuned, on-device model we deployed in the Android app, which due to device resource constraints was smaller and less robust. We achieved a 45% WER improvement compared to our on-device predecessor.
This dramatic decrease in error rate significantly enhances the reliability and trustworthiness of our core speaking feedback loop.
Serving our realtime speech system at scale
In our speaking lessons, we provide instant feedback to our users. This requires streaming speech recognition, where audio is captured as the user speaks and transcriptions are generated and delivered simultaneously. Our ASR system needs to be as fast as possible to provide a real-time interactive experience.
We used Nvidia Riva to serve and deploy our fine-tuned Conformer-CTC model within our own infrastructure. Riva uses Triton Inference Server under the hood to run GPU-powered model inference, and they are both available as container images. We deployed Riva and Triton in our existing Kubernetes cluster, each pod with its own Nvidia GPU. Riva pods scale horizontally with traffic, and our backend services communicate to them with gRPC, a protocol that allows low-latency communication between services.
For client-server communication during a speaking exercise requiring speech recognition, we used websockets to enable real-time, two-way interaction, vital for transmitting audio to our servers and simultaneously getting both interim and final transcription results back.
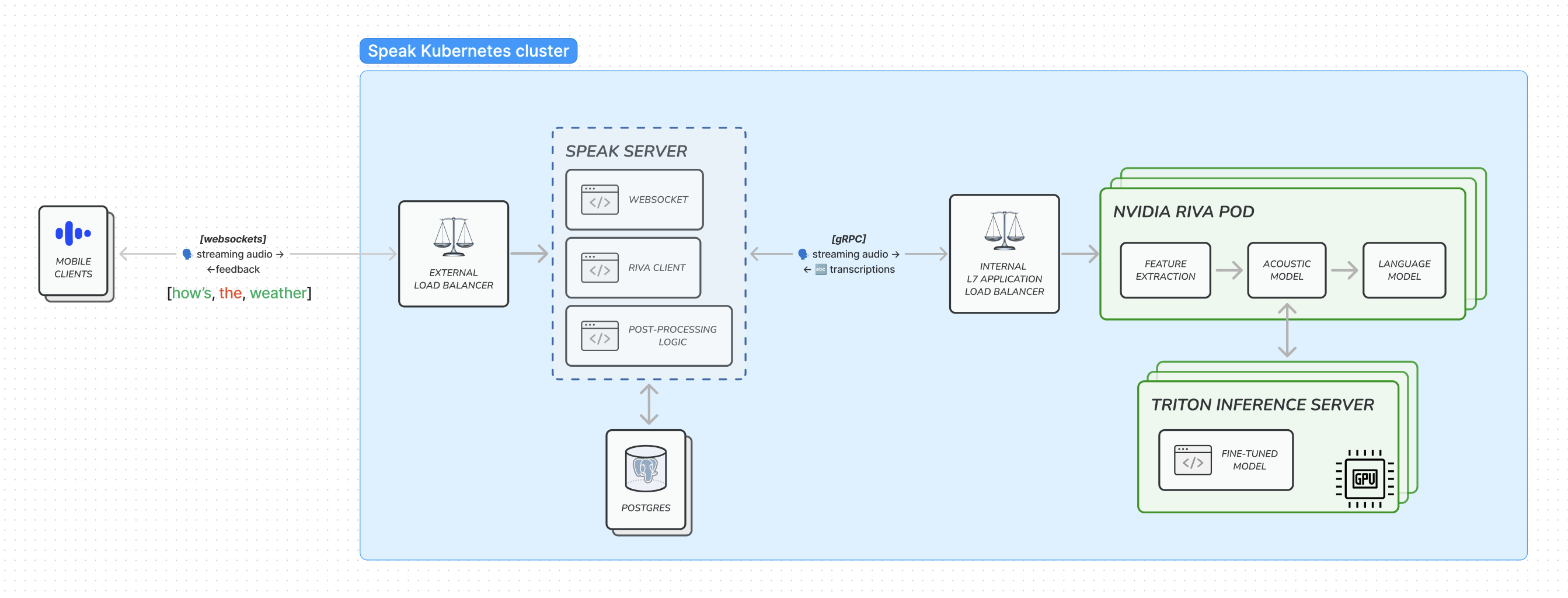
Riva load balancer
Here’s the tricky part: the standard Kubernetes load balancer doesn’t really work with gRPC. By default, it works at the transport layer (L4) and balances requests based on connections, not gRPC remote procedure calls (RPCs). A given gRPC client on a Speak Server pod opens 1 TCP connection and reuses that same connection for all RPCs. So even if the Riva deployment has multiple pods, a pod in our backend server initially connects to only one Riva pod and sends all calls to that pod moving forward, resulting in unbalanced load.
Imagine this as a single cashier at a busy grocery store who handles all the customers, even though there are other cashiers available. This leads to a long line at one cashier while the others are underutilized.
To solve this, we set up a custom L7 application layer load balancer that distributes incoming traffic across all pods in the Riva server, acting like a store manager who directs customers to all available cashiers, ensuring that the workload is evenly distributed and wait times are minimized.
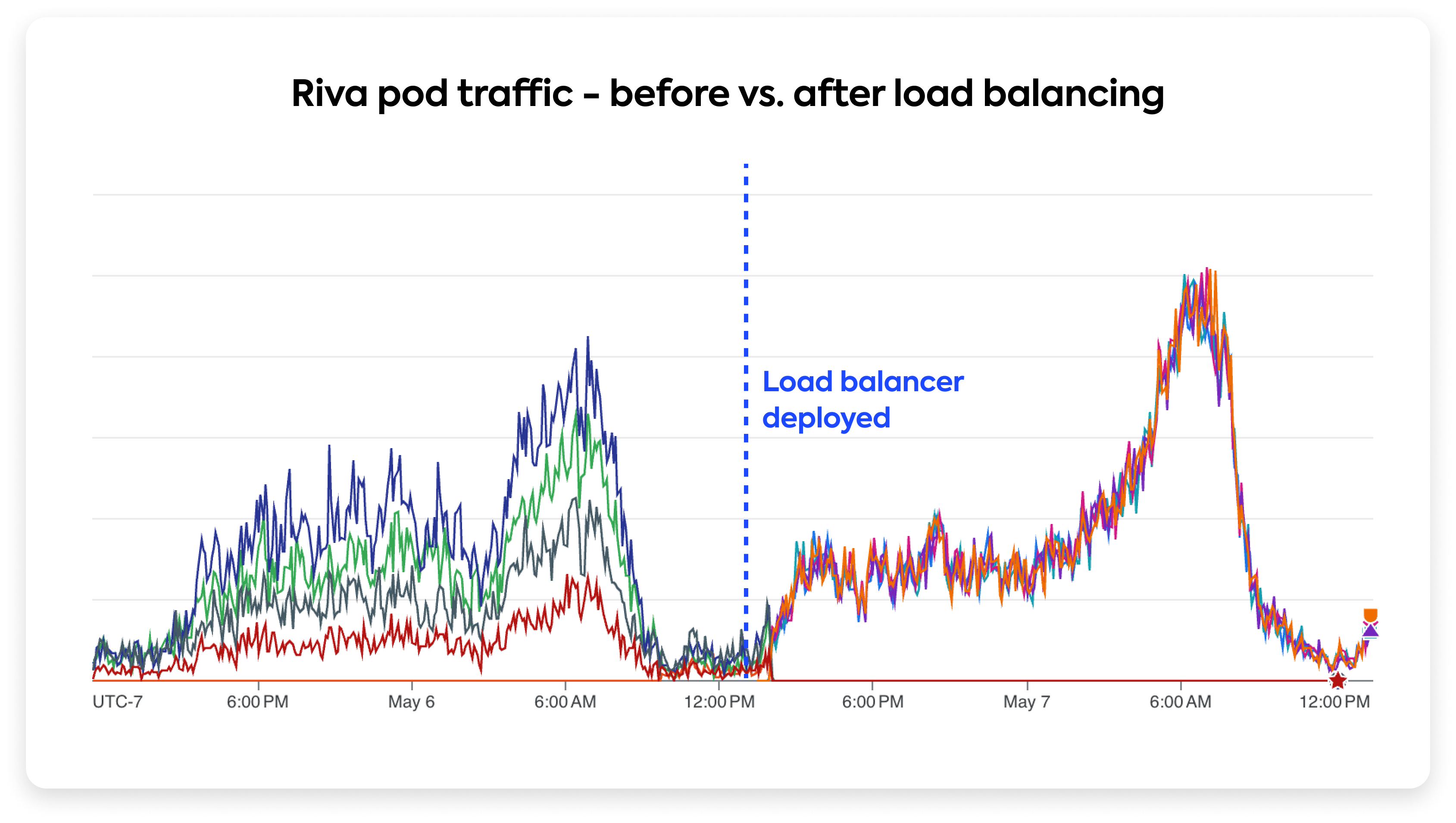
Monitoring system performance metrics
We set up dashboards to monitor the performance of our system, focusing on metrics tailored to streaming, such as: interval between input audio chunks, the frequency of transcript updates, the speed of delivering the first partial transcript, and the total time from start to finish. We also track overall throughput, CPU, GPU, and memory utilization.
How is our new system performing? From the moment we prompt the user to speak and begin recording, it takes about 1.6 seconds on average for the user to receive feedback on their first spoken word. This is a 20% average speed improvement compared to our previous 3rd-party recognition service. We scale Riva pods to match our consistent daily traffic patterns and ensure that feedback is provided at least every 260 milliseconds, aligning closely with the average human reaction time in a conversation (Stivers, et al. 2009).
We also monitor relevant application and business metrics such as word match rate, full line match rate, and line repeat rate (these metrics are specific to how our speaking lessons work). Across all metrics, our new system outperforms not only our previous in-house, fine-tuned model but also major 3rd-party speech recognition systems like Apple Speech and Microsoft Azure Speech.
What’s next?
Our fully revamped core speech systems directly improve the speed and accuracy of speaking feedback given to our learners, as well as set a great unified foundation for continued speech work in the near future.
With all this new model training and deployment infrastructure in place, we’ll be able to quickly iterate on even more modern model architectures and leverage our ever-expanding speech dataset.
Currently, our fine-tuned Conformer-CTC model is used for English speech recognition, but in the near future we’ll be expanding it to Spanish and all the future languages we plan to teach. We’re also working on additional speech and language modalities beyond words (e.g. phonemes for pronunciation feedback).
We’ll also be able to use the same foundational infrastructure to serve custom large language models (LLMs) and multimodal/speech-to-speech models that will unlock amazing novel language learning experiences within Speak.
If you’re interested in this type of applied research and software systems/infrastructure engineering that directly unlocks better & novel product experiences, we’re hiring across many technical roles. Please get in touch at: speak.com/careers